One large issue that I encounter in development with machine learning is the need to structure our data on disk in a way that we can load into Scikit-Learn in a repeatable fashion for continued analysis. My proposal is to use the sklearn.datasets.base.Bunch object to load the data into data and target attributes respectively, similar to how Scikit-Learn’s toy datasets are structured. Using this object to manage our data will mirror the native API and allow us to easily copy and paste code that demonstrates classifiers and techniques with the built in datasets. Importantly, this API will also allow us to communicate to other developers and our future-selves exactly how to use the data.
Moreover, we need to be able to structure more and varied datasets as most projects aren’t dedicated to building a single classifier, but rather lots of them. Data is extracted and written to disk through SQL queries, then models are written back into the database. All of these fixtures (for building models) as well as the extraction method, and meta data need to be versioned so that we can have a repeatable process (for science). The workflow is as follows:
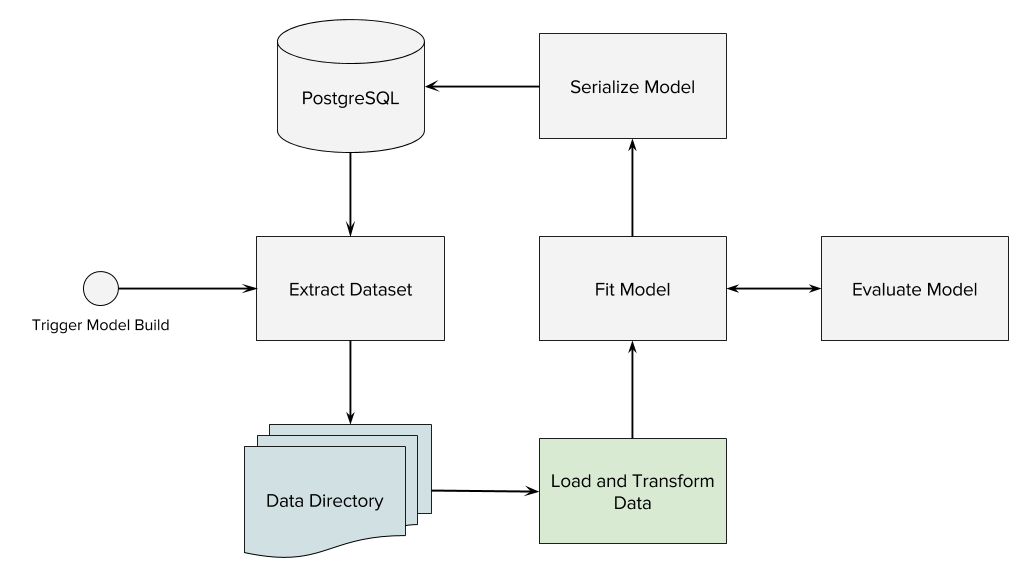
This post is largely concerned with the “Data Directory” and the “Load and Transform Data” highlighted processes in the flow chart. The first step is to structure a fixtures directory with our data code. The fixtures directory will contain named subdirectories where each name is related to a dataset we want to load. These directories will contain the following files.
query.sql: a sql file that can be executed against the database to extract and wrangle the dataset.dataset.txt: a numpy whitespace delimited file containing either a dense or sparse matrix of numeric data to pass to the model fit process. (This can be easily adapted to a CSV file of raw data if needed).README.md: a markdown file containing information about the dataset and attribution. Will be exposed by the DESCR attribute.meta.json: a helper file that contains machine readable information about the dataset like target_names and feature_names.
A very simple project will therefore have a fixtures directory that looks like:
$ project
.
├── fixtures
| ├── energy
| | ├── dataset.txt
| | ├── meta.json
| | ├── README.md
| | └── query.sql
| └── solar
| ├── dataset.txt
| ├── meta.json
| ├── README.md
| └── query.sql
└── index.json
Dataset utilities code should know about this directory and how to access it by using paths relative to the source code and environment variables as follows:
import os
SKL_DATA = "SCIKIT_LEARN_DATA"
BASE_DIR = os.path.normpath(os.path.join(os.path.dirname(__file__), ".."))
DATA_DIR = os.path.join(BASE_DIR, "fixtures")
def get_data_home(data_home=None):
"""
Returns the path of the data directory
"""
if data_home is None:
data_home = os.environ.get(SKL_DATA, DATA_DIR)
data_home = os.path.expanduser(data_home)
if not os.path.exists(data_home):
os.makedirs(data_home)
return data_home
The get_data_home variable looks for the root directory of the fixtures, by accepting a passed in path, or by looking in the environment, finally defaulting to the project fixtures directory. Note that this function creates the directory if it doesn’t exist in order for automatic writes to go through without failing.
The Bunch object in Scikit-Learn is simply a dictionary that exposes dictionary keys as properties so that you can access them with dot notation. This by itself isn’t particularly useful, but let’s look at how the toy datasets are structured:
>>> from sklearn.datasets import load_digits, load_boston
>>> dataset = load_digits()
>>> print dataset.keys()
['images', 'data', 'target_names', 'DESCR', 'target']
>>> print load_boston().keys()
['data', 'feature_names', 'DESCR', 'target']
We can see that the bunch object keeps track of the primary matrix (usually labeled X) in the data attribute and the targets (usually called y) in the target attribute. Moreover, it shows a README with information about the dataset including citations in the DESCR property, as well as other information like names and images. We will create a similar load_data methodology to use in our projects.
Now that we have everything we need stored on disk, we can create a load_data function, which will accept the name of a dataset, and appropriately look it up using the structure above. Moreover, it extracts the data required for a Bunch object including extracting the target value from the first or last columns of the dataset and using the meta.json file for other important information.
import json
import numpy as np
from sklearn.datasets.base import Bunch
def load_data(path, descr=None, target_index=-1):
"""
Returns a sklearn dataset Bunch which includes several important
attributes that are used in modeling:
data: array of shape n_samples * n_features
target: array of length n_samples
feature_names: names of the features
target_names: names of the targets
filenames: names of the files that were loaded
DESCR: contents of the readme
This data therefore has the look and feel of the toy datasets.
"""
root = os.path.join(get_data_home(), path)
filenames = {
'meta': os.path.join(root, 'meta.json'),
'rdme': os.path.join(root, 'README.md'),
'data': os.path.join(root, 'dataset.txt'),
}
target_names = None
feature_names = None
DESCR = None
with open(filenames['meta'], 'r') as f:
meta = json.load(f)
target_names = meta['target_names']
feature_names = meta['feature_names']
with open(filenames['rdme'], 'r') as f:
DESCR = f.read()
dataset = np.loadtxt(filenames['data'])
data = None
target = None
# Target assumed to be either last or first row
if target_index == -1:
data = dataset[:, 0:-1]
target = dataset[:, -1]
elif target_index == 0:
data = dataset[:, 1:]
target = dataset[:, 0]
else:
raise ValueError("Target index must be either -1 or 0")
return Bunch(data=data,
target=target,
filenames=filenames,
target_names=target_names,
feature_names=feature_names,
DESCR=DESCR)
The primary work of the load_data function is to locate the appropriate files on disk, given a root directory that’s passed in as an argument (if you saved your data in a different directory, you can modify the root to have it look in the right place). The meta data is included with the bunch, and is also used split the train and test datasets into data and target variables appropriately, such that we can pass them correctly to the Scikit-Learn fit and predict estimator methods.
Now we can create named aliases for specific datasets as follows:
def load_energy():
return load_data('energy')
def load_solar():
return load_data('solar')
And we have a system that looks and feels exactly like the datasets that Scikit-Learn ships with.