On Tuesday evening I attended a Django District meetup on Grumpy, a transpiler from Python to Go. Because it was a Python meetup, the talk naturally focused on introducing Go to a Python audience, and because it was a Django meetup, we also focused on web services. The premise for Grumpy, as discussed in the announcing Google blog post, is also a web focused one — to take YouTube’s API that’s primarily written in Python and transpile it to Go to improve the overall performance and stability of YouTube’s front-end services.
While still in experimental mode, they show a benchmarking graph in the blog post that shows as the number of threads increases, the number of Grumpy transpiled operations per second also increases linearly, whereas the CPython ops/sec actually decreases to a floor. This is fascinating stuff and actually kind of makes sense; potentially the opportunities for concurrency in Go defeat the GIL in Python and can give Python code deployable scalability.
Still, I wanted to know, if it’s faster, how much faster is it? (skip ahead to results)
In both the meetup talk and the blog post, the fibonacci benchmark is discussed. Unfortunately, neither had raw numbers and since I wanted to try it out on my own anyway, I thought I would. In this post I’ll review the steps I took to use Grumpy then the benchmarking numbers that I came up with.
Getting Started Transpiling
Because the package is in experimental mode, you must download or clone the Grumpy repository and do all your work in the project root directory. This is because relative paths and a couple of special environment variables are required in order to make things work. First clone the repository and change your working directory to the project root:
$ git clone https://github.com/google/grumpy.git
$ cd grumpy
At this point you need to build the grumpy tools and set a couple of environment variables to make things work.
$ make
$ export GOPATH=$PWD/build
$ export PYTHONPATH=$PWD/build/lib/python2.7/site-packages
Note that the make process actually took quite a bit of time on my MacBook, so be patient! I also added the export statements to an .env file locally so that I could easily set the environment for this directory in the future.
The hello world of Grumpy transpiling is quite simple. First create a python file, hello.py:
#!/usr/bin/env python
if __name__ == '__main__':
print "hello world!"
You then transpile it and build a binary executable as follows:
$ build/bin/grumpc hello.py > hello.go
$ go build -o hello hello.go
The first step uses the grumpc transpiler to create Go code from the Python code, and outputs it to the Go source code file, hello.go. The second step uses the go build tool (which requires the $GOPATH to be set correctly) to compile the hello.go program into a binary executable. You can now execute the file directly:
$ ./hello
hello world!
Fibonacci
In order to benchmark the code for time I want to compare three executables:
- A Python 2.7 implementation with recursion (fib.py)
- A pure Go implementation with similar characteristics (fib.go)
- The transpiled Python implementation (fibpy.go)
Note: Obligatory Py2/3 comment: Grumpy is about making the YouTube API better, which is written in Python 2.7; so tough luck Python 3 folks, I guess.
The hypothesis is that the Python implementation will be the slowest, the transpiled one slightly faster and the Go implementation will blaze. For reference, here are my implementations:
#!/usr/bin/env python
import sys
def fib(i):
if i < 2:
return 1
return fib(i-1) + fib(i-2)
if __name__ == '__main__':
try:
idx = sys.argv[1]
print fib(int(idx))
except IndexError:
print "please specify a fibonacci index"
except ValueError:
print "please specify an integer"
The Python implementation is compact and understandable, coming in at 14 lines of code. The Go implementation is slightly longer at 24 lines of code:
package main
import (
"fmt"
"os"
"strconv"
)
func fib(i uint64) uint64 {
if i < 2 {
return uint64(1)
}
return fib(i-1) + fib(i-2)
}
func main() {
if len(os.Args) != 2 {
fmt.Println("please specify a fibonacci index")
os.Exit(1)
}
idx, err := strconv.ParseUint(os.Args[1], 10, 64)
if err != nil {
fmt.Println("please specify an integer")
os.Exit(1)
}
fmt.Println(fib(idx))
}
In order to transpile the code, build it as follows:
$ $ build/bin/grumpc fib.py > fibpy.go
$ go build -o fibpy fibpy.go
And of course build the go code as well:
$ go build -o fib fib.go
The transpiled code comes in at a whopping 255 lines of code, so I’ll not show it here, but if you’re interested you can find it at this gist.
One interesting thing about Grumpy is it uses a
πsymbol for variable names that reference Python, for example, the grumpy package is imported into the namespaceπg.
So in terms of code, we have the following characteristics:
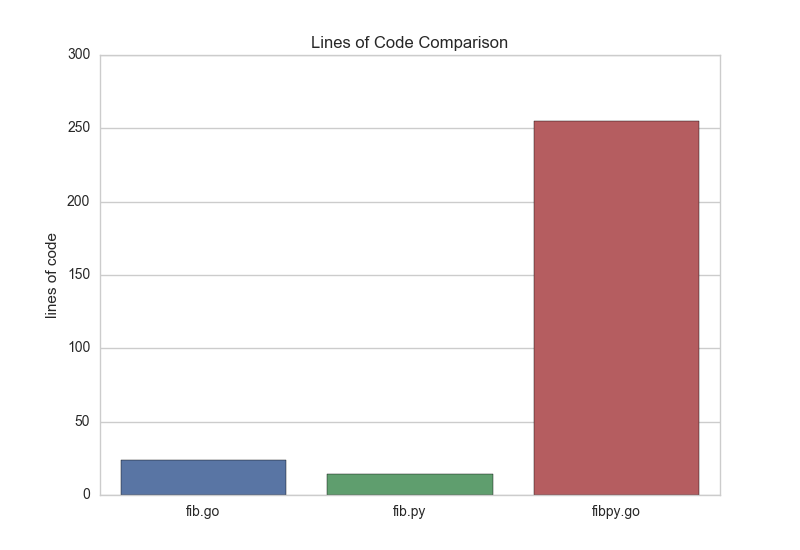
But frankly that’s fair — Grumpy has to do a lot of work to bring over the sys package from Python, handle exceptions in the try/except, handle the builtins and deal with objects and function definitions. I actually think Grumpy is doing pretty well in the translation in terms of LOC.
Benchmarking
Typically I would use Go benchmarking to measure the performance of an operation — it is both formal and does a good job of doing micro-measurements in terms of number of operations per second. However, I can’t use this technique for the Python code and I want to make sure that we can capture the benchmarks for the complete executable including imports like the sys module. Therefore the benchmarks are timings of complete runs of the executables, the equivalent of:
$ time ./fib 40
$ time ./fibpy 40
$ time python fib.py 40
Because the recursive fibonacci implementation does not use memoization or dynamic programming, the computational time increases exponentially as the index gets higher. Therefore the benchmarks are several runs at moderately high indices to push the performance. In order to operationalize this, I wrote a small Python script to execute the benchmarks. You can find the benchmark script on Gist (it is a bit too large to include in this post).
NOTE: I hope that I have provided everything needed to repeat these benchmarks. If you find a hole in the methodology or different results, I’d certainly be interested.
After the timing benchmarks I also wanted to run resource usage benchmarks. Since the fibonacci implementation currently doesn’t use multiple threads, I can’t compare run times across increasing number of processes (TODO!). Instead, using the memory profiler library I simply measured memory usage. In the results section, I run each process using mprof independently in order to precisely track what is running where. However, using the new multiprocess feature of the memory profiler library you could create a bash script as follows:
#!/bin/bash
./fib $1 &
./fibpy $1 &
python fib.py $1 &
wait
And run the memory profiler on each of the processes:
$ mprof run -M ./fibmem.sh 40
$ mprof plot
This will background each of the processes so that they are plotted as child processes of the main bash script. Unfortunately they are plotted by index, so it’s hard to know which child is which, but I believe that child 0 is the go implementation, child 1 is the transpiled implementation, and child 2 is the Python implementation. Ok, so after that long description of methods, let’s get into findings.
Results
For 20 runs of each executable for fibonacci arguments 25, 30, 35, and 40, I recorded the following average times for the various executables shown in the next figure. Note that the amount of time for the next argument increases exponentially, opening up the performance gap between executables.
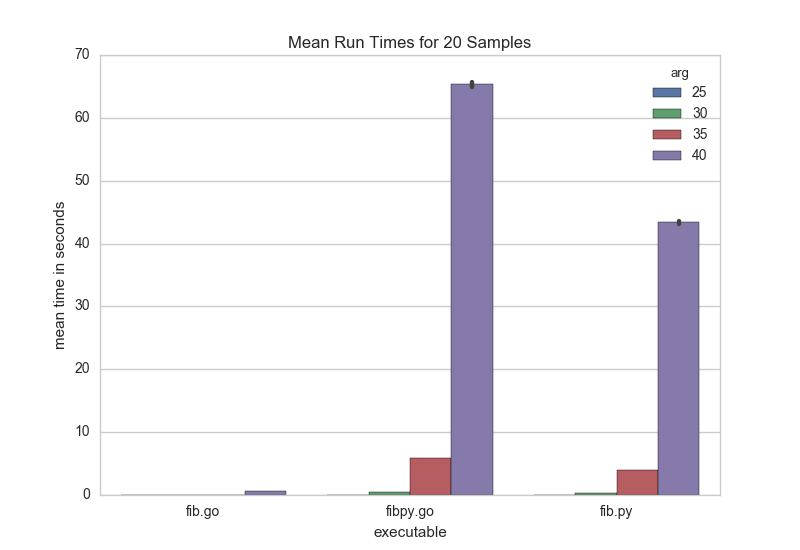
Unsurprisingly, the pure Go implementation was blazing fast, about 42 times faster than the Python implementation on average. The real surprise, however, is that the transpiled Go was actually 1.5 times slower than the Python implementation. I actually cannot explain why this might be — I’m hugely curious if anyone has an answer.
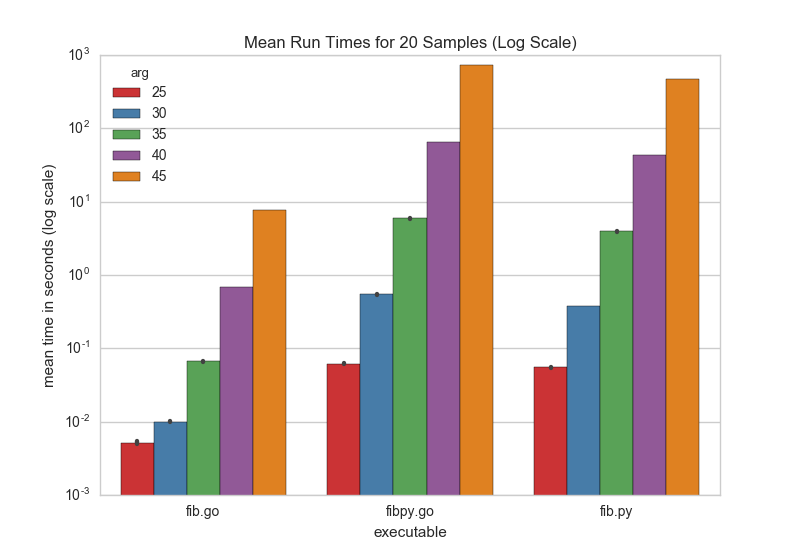
In order to give a clearer picture, here are the log scaled results with a fifth timing for the 45th fibonacci number computation:
In order to track memory usage, I used mprof to track memory for each executable ran independently in it’s own process, here are the results:
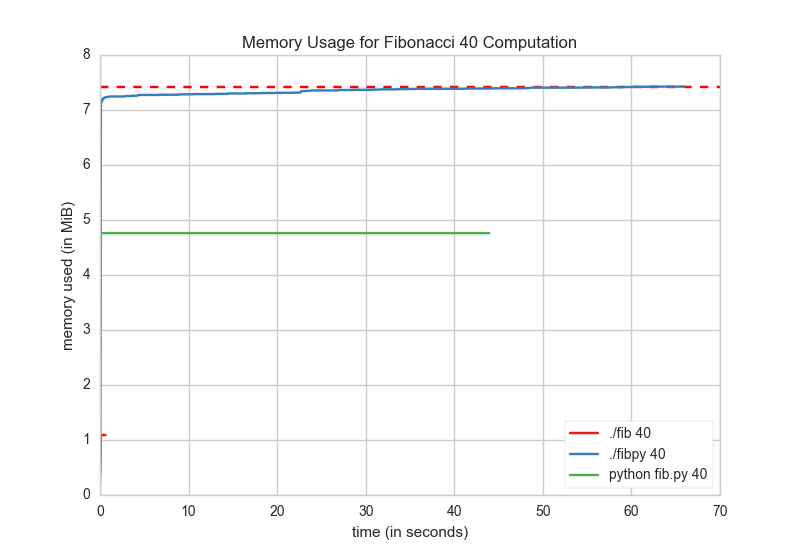
And so that you can actually see the pure Go implementation as well as memory usage initialization and start up, here is a zoomed in version to the first few milliseconds of execution:
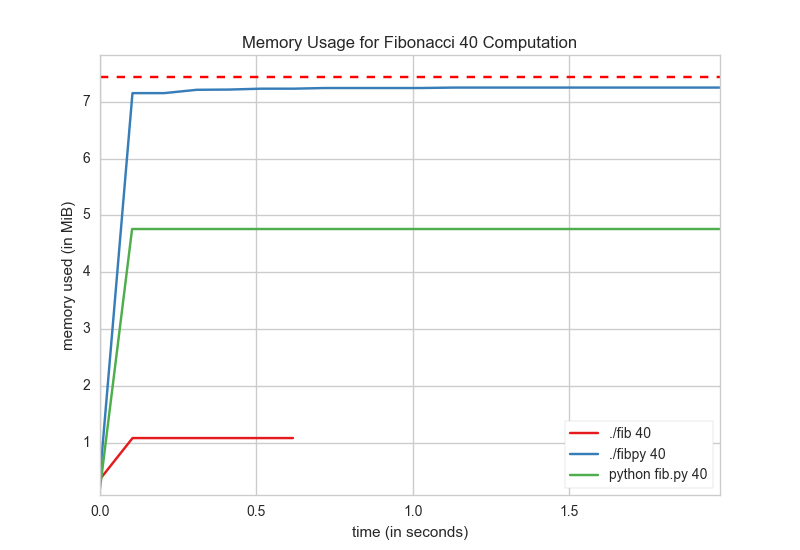
The memory usage profiling reveals yet another surprise, not only does the transpiled version take longer to execute, but it also uses more memory. Meanwhile, the pure go implementation is so lightweight as to blow away with a stiff breeze.
Conclusions
Transpiling is hard.
Grumpy is still only experimental, and there does seem to be some real promise particularly with concurrency gains. However, I’m not sold on transpiling as an approach to squeezing more performance out of a system.