One of the projects I’m currently working on is the ingestion of RSS feeds into a Mongo database. It’s been running for the past year, and as of this post has collected 1,575,987 posts for 373 feeds after 8,126 jobs. This equates to about 585GB of raw data, and a firm requirement for compression in order to exchange data.
Recently, @ojedatony1616 downloaded the compressed zip file (53GB) onto a 1TB external hard disk and attempted to decompress it. After three days, he tried to cancel it and ended up restarting his computer because it wouldn’t cancel. His approach was simply to double click the file on OS X, but that got me to thinking – it shouldn’t have taken that long; why did it choke? Inspecting the export logs on the server, I noted that it took 137 minutes to compress the directory; shouldn’t it take that long to decompress as well?
A quick Google revealed A Quick Benchmark: Gzip vs. Bzip2 vs. LZMA, written in 2005 to explore the performance of Gzip, Bzip2, and LZMA. This post cited Gzip as having the largest final compression size, but the fastest compression speed. Being 12 years ago, however, I wanted to get more modern numbers for the compression of a directory of many intermediately sized files. Hopefully this will help us make better decisions about data management and compression in the future.
In particular, these observations explore the compression ratio and speed of Tar Gzip, Tar Bzip2, and Zip on directories containing many intermediate sized files from 1MB to 10MB.
Results
The following results were recorded on the following platform:
- 2.8GHz Intel Core i7 Macbook Pro
- 16GB DDR3 Memory and 750GB Flash Storage Disk
- OS X El Capitan Version 10.11.6
- bsdtar 2.8.3 - libarchive 2.8.3
- Apple gzip 251
- bzip2 version 1.0.6, 6-Sept-2010
- Zip 3.0 (July 5th 2008), by Info-ZIP
As always, performance measurements are determined by a number of factors, use these results as a guide rather than as strict truth!
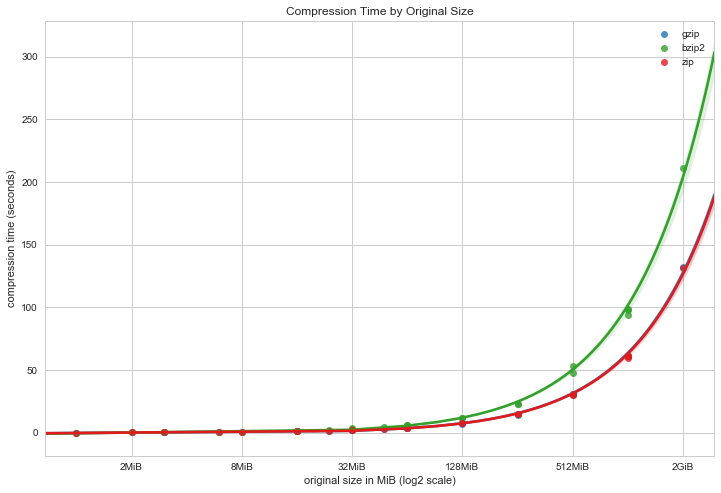
In the first chart we explore the amount of time it takes to compress a large directory. There is linear relationship between the size of the directory and the amount of time it takes to compress it, which makes sense. BZip2 takes the longest, and Zip and GZip are comparable in terms of the overall amount of time.
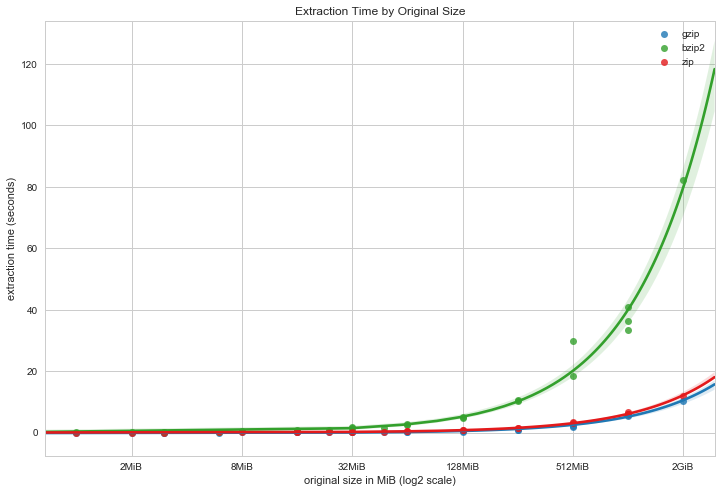
We get a similar result for extraction time, though clearly extraction is much faster than compression. BZip2 is once again the slowest, but although Zip and GZip are still comparable at lower file sizes, GZip appears to be taking an advantage at the larger archives. We’ll have to explore this more with much larger archives.
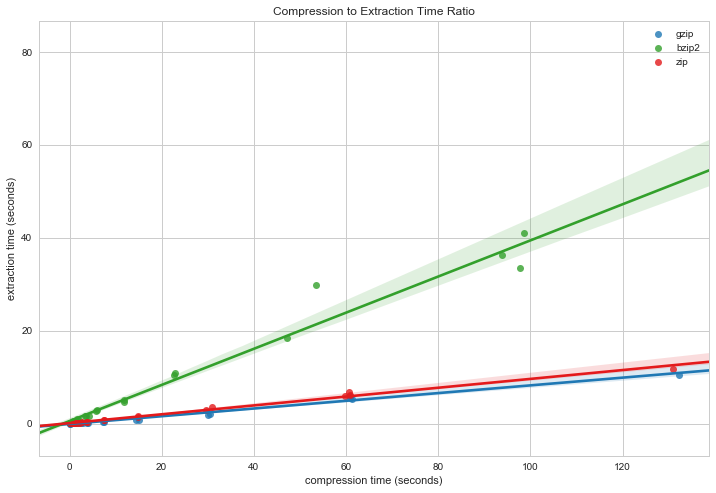
Compression to extraction times appear to have a nearly linear relationship. When plotted against each other, we can see that indeed the slope of Zip is slightly larger than that of GZip and in fact there will be a measurable difference for larger file sizes!
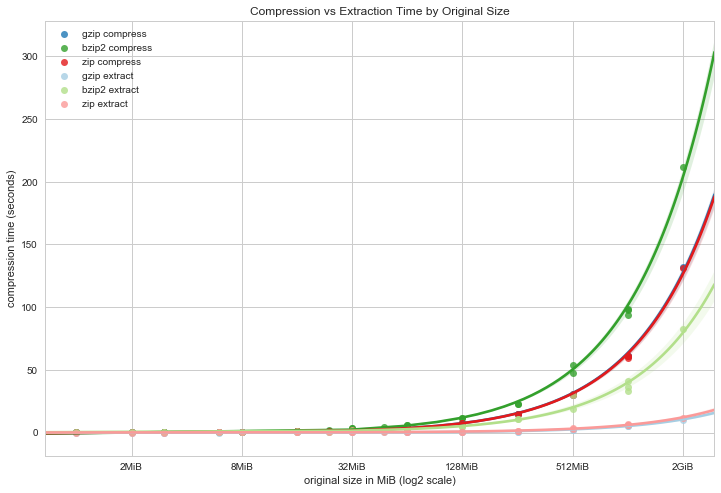
The above graph simply shows both the compression and extraction times and their relationship to each other.
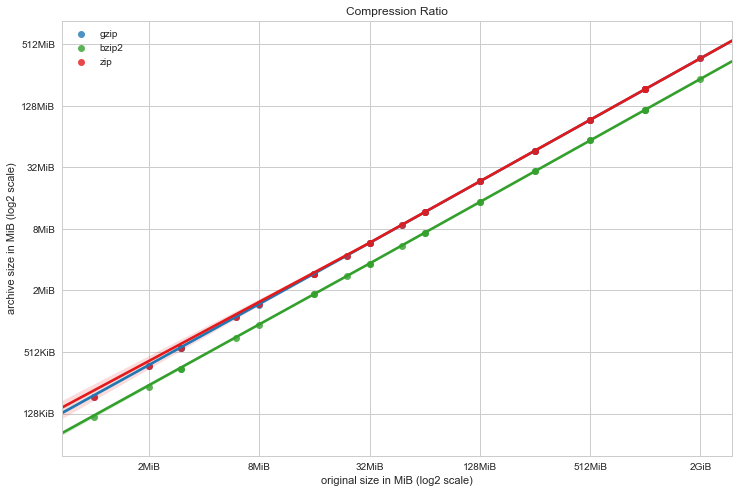
Looking at how much we’ve compressed, we can compute the compression ratio: plotting the size of the original data to the archive size. This is a log-log scale, and we can see that BZip2 creates smaller archives at the cost of the time performance hit. BZip2 appears to be parallel with GZip, but GZip appears to have a slightly larger slope than Zip, doing better at smaller archive sizes and may eventually do even better at much larger file sizes.
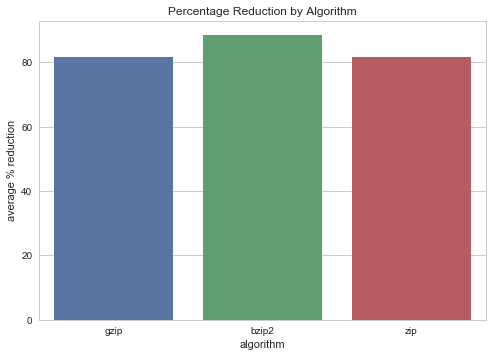
All compression algorithms of course reduce huge amounts of dataset space when reducing text, around 80% reductions for Zip and GZip and over 90% reduction for BZip2.
Because of this result, it’s clear that instead of compressing the entire directory, we should instead compress each individual file, extracting them only as necessary as we need to read them in.
Method
The goal of this benchmark was to explore compression and extraction of a directory containing many small files (similar to the corpus dataset we are dealing with). The files in question are text, json, or html, which compress pretty well. Therefore I created a dataset generation script that used the lorem package to create random text files of various sizes (1MiB and 2MiB files to start).
Each directory contained 8 subdirectories with n files in each directory, which determines the total size of the dataset. For example, the 64MiB dataset of 1MiB files contained 8 files per subdirectory. The benchmark script first walked the data directory to get an exact file size, then compressed it using the specified tool. It computed the archive size to get the percent compression, then extracted the file to a temporary directory. Both compression and extraction was timed.
For more details, please see the script used to generate test data sets and run benchmarks on Gist: zipbench.py.
For future work I’d like to build this up to much larger corpus sizes, but that will probably require AWS or some dedicated hardware other than my MacBook pro, and a lot more time!