Syntactic parsing is a technique by which segmented, tokenized, and part-of-speech tagged text is assigned a structure that reveals the relationships between tokens governed by syntax rules, e.g. by grammars. Consider the sentence:
The factory employs 12.8 percent of Bradford County.
A syntax parse produces a tree that might help us understand that the subject of the sentence is “the factory”, the predicate is “employs”, and the target is “12.8 percent”, which in turn is modified by “Bradford County”. Syntax parses are often a first step toward deep information extraction or semantic understanding of text. Note however, that syntax parsing methods suffer from structural ambiguity, that is the possibility that there exists more than one correct parse for a given sentence. Attempting to select the most likely parse for a sentence is incredibly difficult.
The best general syntax parser that exists for English, Arabic, Chinese, French, German, and Spanish is currently the blackbox parser found in Stanford’s CoreNLP library. This parser is a Java library, however, and requires Java 1.8 to be installed. Luckily it also comes with a server that can be run and accessed from Python using NLTK 3.2.3 or later. Once you have downloaded the JAR files from the CoreNLP download page and installed Java 1.8 as well as pip installed nltk, you can run the server as follows:
from nltk.parse.corenlp import CoreNLPServer
# The server needs to know the location of the following files:
# - stanford-corenlp-X.X.X.jar
# - stanford-corenlp-X.X.X-models.jar
STANFORD = os.path.join("models", "stanford-corenlp-full-2018-02-27")
# Create the server
server = CoreNLPServer(
os.path.join(STANFORD, "stanford-corenlp-3.9.1.jar"),
os.path.join(STANFORD, "stanford-corenlp-3.9.1-models.jar"),
)
# Start the server in the background
server.start()
The server needs to know the location of the JAR files you downloaded, either by adding them to your Java $CLASSPATH or like me, storing them in a models directory that you can access from your project. When you start the server, it runs in the background, ready for parsing.
To get constituency parses from the server, instantiate a CoreNLPParser and parse raw text as follows:
from nltk.parse.corenlpnltk.pa import CoreNLPParser
parser = CoreNLPParser()
parse = next(parser.raw_parse("I put the book in the box on the table."))
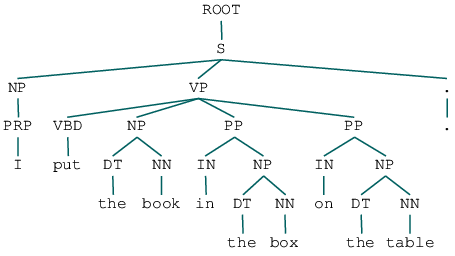
If you’re in a Jupyter notebook, the tree will be drawn as above. Note that the CoreNLPParser can take a URL to the CoreNLP server, so if you’re deploying this in production, you can run the server in a docker container, etc. and access it for multiple parses. The raw_parse method expects a single sentence as a string; you can also use the parse method to pass in tokenized and tagged text using other NLTK methods. Parses are also handy for identifying questions:
next(parser.raw_parse("What is the longest river in the world?"))
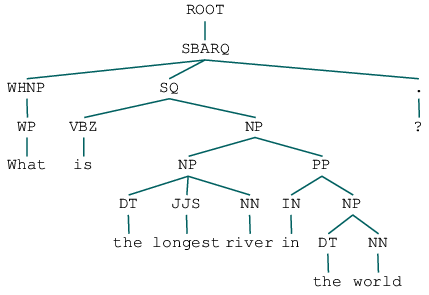
Note the SBARQ representing the question; this data can be used to create a classifier that can detect what type of question is being asked, which can then in turn be used to transform the question into a database query!
I should also point out why we’re using next(); the parser actually returns a generator of parses, starting with the most likely. By using next, we’re selecting only the first, most likely parse.
Constituency parses are deep and contain a lot of information, but often dependency parses are more useful for text analytics and information extraction. To get a Stanford dependency parse with Python:
from nltk.parse.corenlp import CoreNLPDependencyParser
parser = CoreNLPDependencyParser()
parse = next(parser.raw_parse("I put the book in the box on the table."))

Once you’re done parsing, don’t forget to stop the server!
# Stop the CoreNLP server
server.stop()
To ensure that the server is stopped even when an exception occurs, you can also use the CoreNLPServer context manager as follows:
jars = (
"stanford-corenlp-3.9.1.jar",
"stanford-corenlp-3.9.1-models.jar"
)
with CoreNLPServer(*jars):
parser = CoreNLPParser()
text = "The runner scored from second on a base hit"
parse = next(parser.parse_text(text))
parse.draw()
Note that the parse_text function in the above code allows a string to be passed that might contain multiple sentences and returns a parse for each sentence it segments. Additionally the tokenize and tag methods can be used on the parser to get the Stanford part of speech tags from the text.
Unfortunately there isn’t much documentation on this, but for more check out the NLTK CoreNLP API documentation.