Blast throughput is what we call a throughput measurement such that N requests are simultaneously sent to the server and the duration to receive responses for all N requests is recorded. The throughput is computed as N/duration where duration is in seconds. This is the typical and potentially correct way to measure throughput from a client to a server, however issues do arise in distributed systems land:
- the requests must all originate from a single client
- high latency response outliers can skew results
- you must be confident that N is big enough to max out the server
- N mustn’t be so big as to create non-server related bottlenecks.
In this post I’ll discuss my implementation of the blast workload as well as an issue that came up with many concurrent connections in gRPC. This led me down the path to use one connection to do blast throughput testing, which led to other issues, which I’ll discuss later.
First, let’s suppose that we have a gRPC service that defines a unary RPC with a Put() interface that allows the storage of a string key and a bytes value with protocol buffers. The blast throughput implementation is as follows:
This is a lot of code to go through but the key parts of this are as follows:
- As much work as possible is done before executing the blast, e.g. creating request objects and connecting the clients to the server.
- Synchronization is achieved through arrays of length N - no channels or locks are used for reporting purposes.
- The only thing each blast operation executes is the creation of a context and sending the request to the server.
I created a simple server that wrapped a map[string][]byte with a sync.RWMutex and implemented the Put service. It’s not high performance, sure, but it should highlight how well Blast works as well as the performance of a minimal gRPC server, the results surprised me:
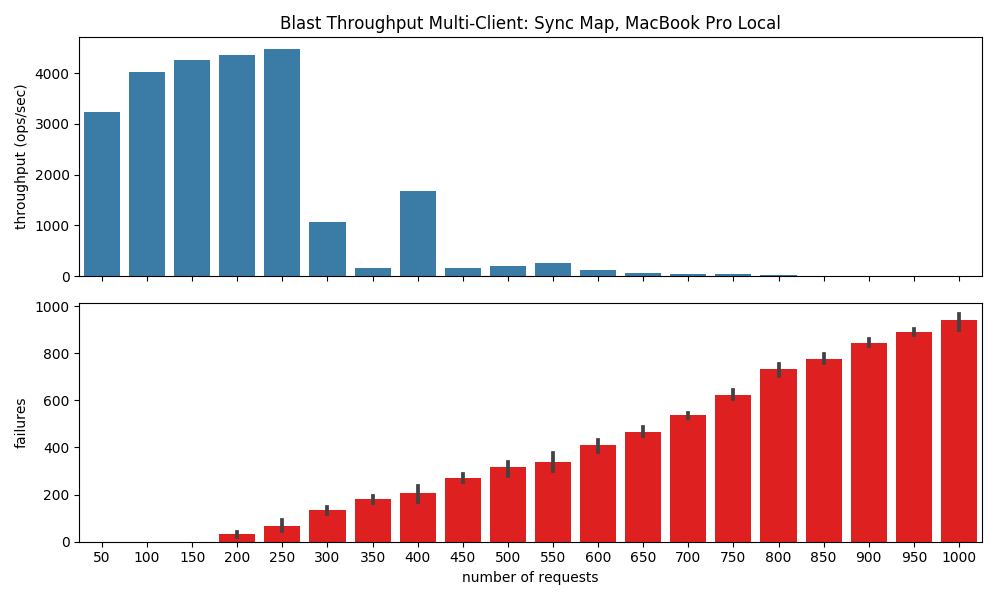
The top graph shows the throughput, a terrible 4500 ops/second for only 250 blasted requests, and worse, after 250 requests the throughput drops to nothing, because as you can see from the bottom graph, the failures start to increase.
Printing out the errors I was getting rpc error: code = Unavailable desc = transport is closing errors from gRPC. All 1000 clients successfully connected, but then could not make requests.
The fix, as mentioned on line 41 was to replace the client per request with a single client (or possible a handful of clients that are used in a round-robin fashion by each request). This improved things significantly:
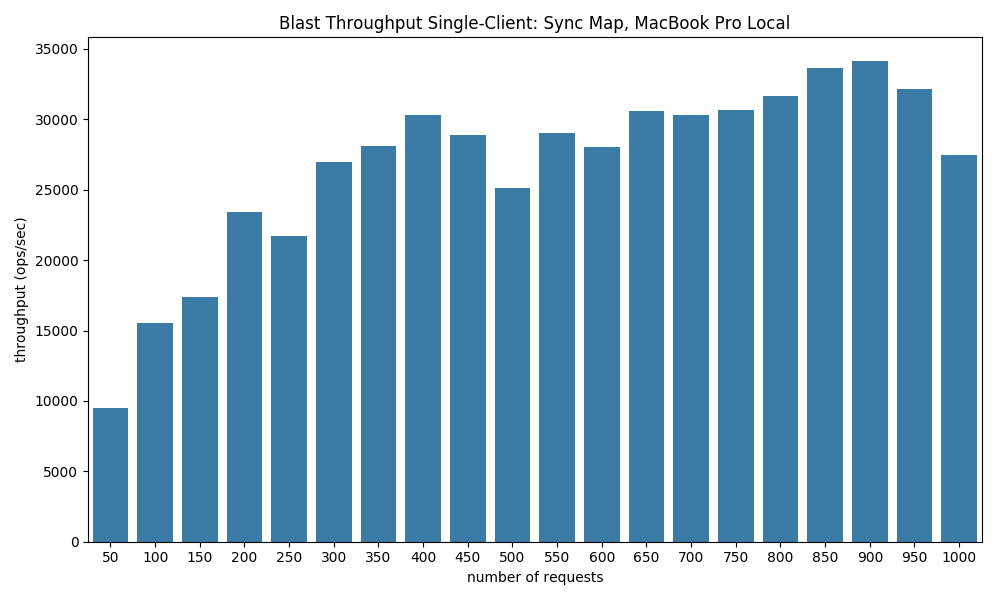
Now we’re getting 30,000 puts per second, which is closer to what I would expect from gRPC’s Unary RPC. However, using a single client does pose some issues:
- The client must be thread safe when making requests, which could add additional overhead to the throughput computation.
- Dealing with redirects or other server-side errors may become impossible with a single client blast throughput measurement.
- How do you balance the blast against multiple servers?
The complete implementation of Blast and the server can be found at github.com/bbengfort/speedmap in the server-blast branch in the server folder.
Note that I just found strest-grpc, which I’m interested in figuring out how it matches up with this assesment and blog post.
In a later post, I’ll discuss how we implement sustained throughput - where we have multiple clients continuously writing to the system and we measure throughput server-side.