Performance is key when building streaming gRPC services. When you’re trying to maximize throughput (e.g. messages per second) benchmarking is essential to understanding where the bottlenecks in your application are.
However, as a start, you can pretty much guarantee that one bottleneck is going to be the serialization (marshaling) and deserialization (unmarshaling) of protocol buffer messages.
We have a use case where the server does not need all of the information in the message in order to process the message. E.g. we have header information such as IDs and client information that the server does need to update as part of processing. The other part of the message is data that needs to be saved to disk and does not have to be unmarshaled until it’s read. However, our protocol buffer schema right now is “flat” — meaning that all fields whether they are required for processing or not are defined by a single protocol buffer message.
So we thought - could we break the flat protocol buffer message into two parts with one part wrapping the other? E.g. the outer message contains just the information the server needs for processing and the inner message remains marshalled until it is needed? Would this increase the performance of marshaling and unmarshaling?
The answer surprised me — yes, sort of. In the figure below, smaller throughput is better (e.g. it is faster):
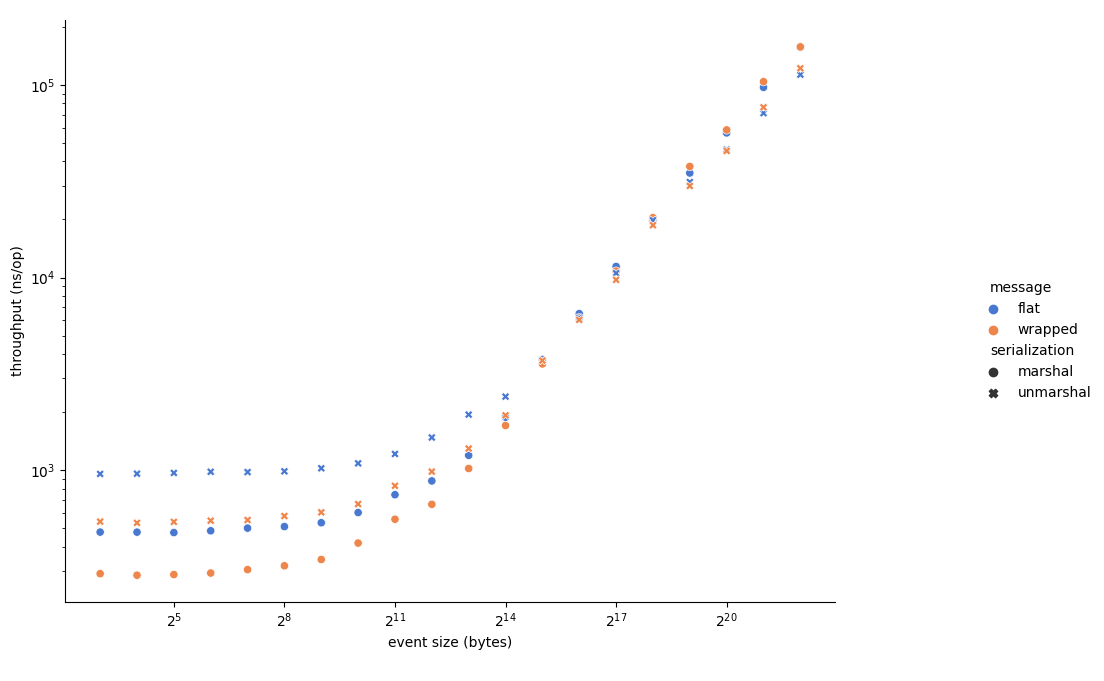
The event size in this case is the size of the inner message which is just bytes. When the event size is “small” (less than 16KiB) then having a wrapped message outperforms the flat message for both marshaling and unmarshaling. However, as the inner message gets larger, serialization of the flat message gets faster.
My hypothesis for this is that the serializing a fixed-size outer wrapper is a constant cost; but the serializer does still have to read the entire data field into memory. At some point the time that reading the data field into memory takes starts to outweigh the benefits of the wrapper object.
Also, don’t get me wrong; overall it will take longer to serialize the entire message. The client will have to first serialize the inner message, then the outer message, which will take longer on the client side; and when reading the inner message will have to be deserialized again. However, having the client do the work does increase the throughput of the server, so it’s worth it to us.
Also, in the case of unmarshaling when you have nested types, the number of allocs falls by the number of nested types in the inner struct - another bonus!
The full code for this benchmark can be found here:
More detailed results:
Tiny/FlatMarshal-10 1945454 607.1 ns/op 1536 B/op 1 allocs/op
Tiny/WrappedMarshal-10 2869138 418.6 ns/op 1536 B/op 1 allocs/op
XSmall/FlatMarshal-10 1202126 919.8 ns/op 4864 B/op 1 allocs/op
XSmall/WrappedMarshal-10 1773110 797.0 ns/op 4864 B/op 1 allocs/op
Small/FlatMarshal-10 1000000 1217 ns/op 9472 B/op 1 allocs/op
Small/WrappedMarshal-10 1000000 1076 ns/op 9472 B/op 1 allocs/op
Medium/FlatMarshal-10 331611 3792 ns/op 40960 B/op 1 allocs/op
Medium/WrappedMarshal-10 335064 3512 ns/op 40960 B/op 1 allocs/op
Large/FlatMarshal-10 18306 64584 ns/op 1474560 B/op 1 allocs/op
Large/WrappedMarshal-10 16376 69056 ns/op 1474561 B/op 1 allocs/op
XLarge/FlatMarshal-10 7090 167709 ns/op 5251074 B/op 1 allocs/op
XLarge/WrappedMarshal-10 6192 174831 ns/op 5251075 B/op 1 allocs/op
Tiny/FlatUnmarshal-10 1000000 1102 ns/op 2280 B/op 24 allocs/op
Tiny/WrappedUnmarshal-10 1783885 691.9 ns/op 2008 B/op 14 allocs/op
XSmall/FlatUnmarshal-10 794436 1528 ns/op 5352 B/op 24 allocs/op
XSmall/WrappedUnmarshal-10 1256288 942.3 ns/op 5464 B/op 14 allocs/op
Small/FlatUnmarshal-10 631819 1936 ns/op 9448 B/op 24 allocs/op
Small/WrappedUnmarshal-10 986050 1243 ns/op 10072 B/op 14 allocs/op
Medium/FlatUnmarshal-10 320212 3653 ns/op 34024 B/op 24 allocs/op
Medium/WrappedUnmarshal-10 322702 3714 ns/op 41560 B/op 14 allocs/op
Large/FlatUnmarshal-10 21088 52541 ns/op 1475816 B/op 24 allocs/op
Large/WrappedUnmarshal-10 19327 56723 ns/op 1475160 B/op 14 allocs/op
XLarge/FlatUnmarshal-10 8012 131589 ns/op 5252329 B/op 24 allocs/op
XLarge/WrappedUnmarshal-10 8575 146534 ns/op 5251674 B/op 14 allocs/op